Query Snowflake Iceberg tables with DuckDB & Spark to Save Costs
As a big fan of data lake formats such as Apache Iceberg, when Snowflake announced that Iceberg tables were in general availability, I wanted to investigate how I can utilise them for my workloads. Snowflake's Iceberg Catalog, Polaris Catalog, was one of the biggest announcements in Snowflake Summit and Databricks acquired Tabular, the company by the creators of Apache Iceberg for more than $1B around the same time.
Iceberg is interestingly the main agenda of Snowflake's 2024 Q4 earnings call as well. You can read the transcript from the earnings call here. An interesting question from Morgan Stanley caught my attention from the call:
For fiscal year '25, I think you assumed a number of large customers going to adopt Iceberg Table. So, some expectations of data moving out of Snowflake losing some storage revenue and some compute revenue there. Can you just double-click on why some of the existing large customers are going to choose Iceberg Table rather than their original?
Mike Scarpelli -- Chief Financial Officer, answered as follows:
A lot of big customers want to have open file formats, to give them options. And by the way, this is not necessarily customers moving all of their storage out of Snowflake, but a lot of the growth in their storage will be put into Iceberg Tables is what we think is going to happen. So, you're just not going to see the growth associated with the storage in many of those customers. As a reminder, about 10% to 11% of our overall revenue is associated with storage.
Enterprise companies don't want vendor-lock so they're the ones pushing Databricks + Snowflake to adopt open data lake formats such as Iceberg. There is no performance penalty for using these data lake formats, the query & ingestion latency is same as Snowflake's native tables.
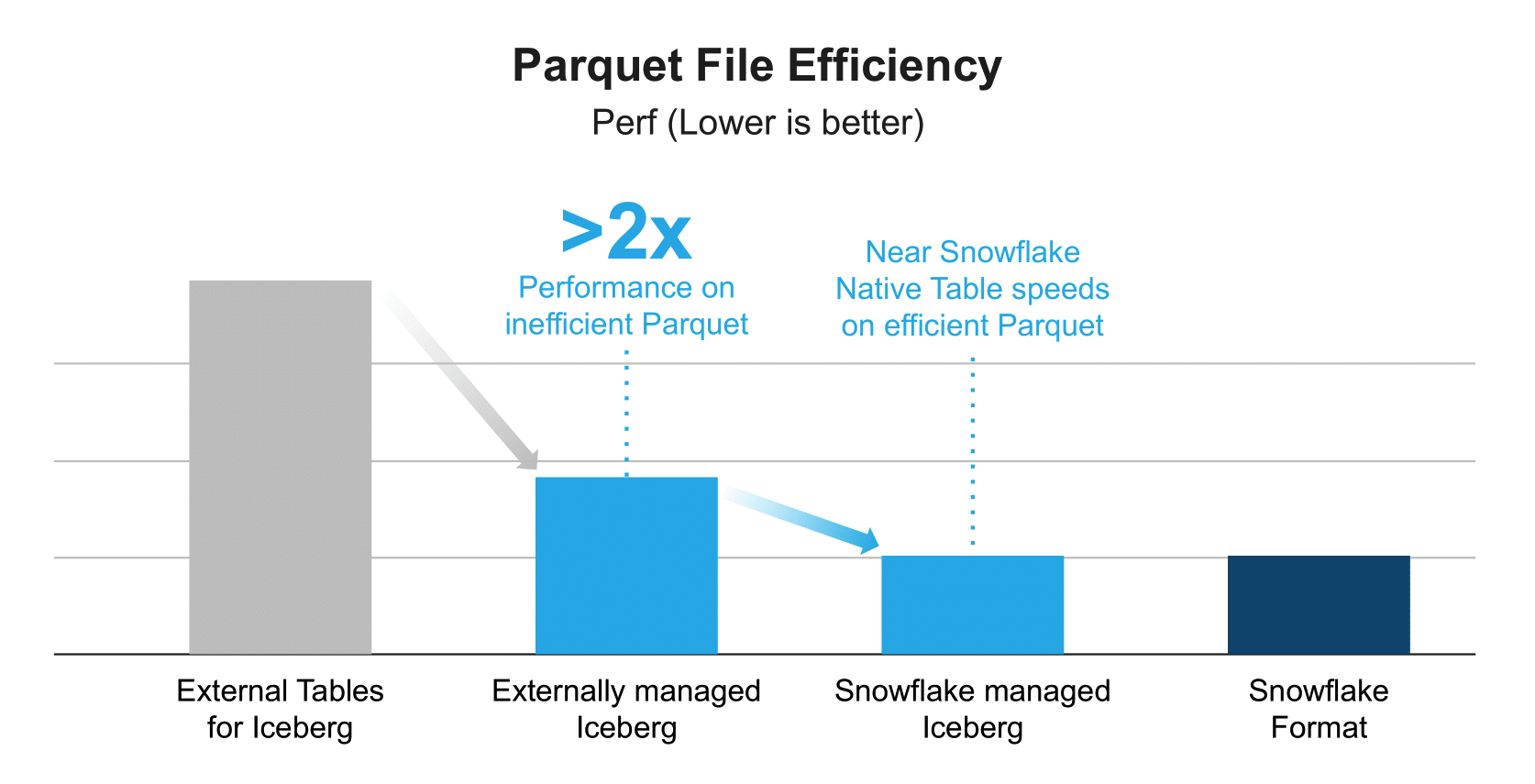
An interesting that the assumption here is that Iceberg will mostly affect the storage revenue as the customers now store the data in their data lake but not in Snowflake's table format on their object storage. This doesn't seem to be a threat to Snowflake as compute makes 9x revenue compared to storage at Snowflake. Although storage revenue will be directly affected, I don't think this assumption is correct though because Iceberg also enables data ingestion, transformation, and querying to be outside of Snowflake.
Compute Pricing
As a power user of Snowflake, the reason why I love their product is that almost all my queries just work. I don't need to tune the warehouse or often don't need to tune the queries much. I don't see out-of-memory errors but when they're slow, I just switch to a bigger warehouse and it just speeds up the query respectively. They have their credit-based pricing with support for different warehouse size as follows:

| Warehouse Size | Credits / Hour |
|---|---|
| X-Small | 1 |
| Small | 2 |
| Medium | 4 |
| Large | 8 |
| X-Large | 16 |
| 2X-Large | 32 |
While it's a relief not to worry about whether my queries run or not, a majority of the time, I try to use the smallest warehouse size, X-Small. The best practice is to enable auto-suspend, which suspends the warehouse after a certain time of inactivity. Snowflake charges 60 seconds minimum for these warehouses, even though your query is executed in under a second though so it's best to batch the queries together.
I find it annoying that the smallest compute unit, X-Small, costs $2.00 hourly because on AWS and GCP, you can get 200GB of memory within the price range and they're considered high-end machines. More interestingly, if your computer has more than 16GB of memory, you can likely use your computer's CPU for free and avoid utilising Snowflake's smallest warehouse when you use Iceberg.
Ingestion with Iceberg
Snowflake has stages to load data from the data lake into Snowflake. You can create data pipelines using Snowflake streams and tasks, and pipes. This approach is more Snowflake native and SQL-based. While it's not as flexible as Spark, it's much easier to develop and maintain.
CREATE OR REPLACE ICEBERG TABLE my_iceberg_table (
boolean_col boolean,
int_col int,
long_col long,
float_col float,
double_col double
)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'my_ext_vol'
BASE_LOCATION = 'my/relative/path/from/extvol';
COPY INTO my_iceberg_table(boolean_col, int_col, long_col, float_col, double_col)
from (select t.$1, t.$2, t.$6, t.$7 from @mystage/sales.csv.gz t)
FILE_FORMAT = (FORMAT_NAME = mycsvformat);
Snowflake also started targeting Spark using its flavour of Spark, called Snowpark. It was probably the second hot topic after Iceberg in Snowflake Summit as Snowflake wants to eat Databricks's lunch but in terms of ecosystem, Spark is still winning thanks for its ecosystem.
If you're already using Databricks / Google Dataproc / AWS EMR, you can use Spark's Iceberg integration to write Iceberg tables without using Snowflake's compute. Later, you can use Snowflake's object storage catalog to create Iceberg tables. If you have AWS / GCP credits, generate data on the fly using Spark and have huge data sets, this approach can save you a lot of money because you don't need to pay for Snowflake's compute:
CREATE OR REPLACE CATALOG INTEGRATION icebergCatalogInt
CATALOG_SOURCE=OBJECT_STORE
TABLE_FORMAT=ICEBERG
ENABLED=TRUE;
CREATE ICEBERG TABLE table_name
CATALOG = 'icebergCatalogInt'
EXTERNAL_VOLUME = 'your_data_lake_volume'
METADATA_FILE_PATH='path/to/metadata/v1.metadata.json'
If you're not ingesting huge datasets but rather small files, Iceberg is a bit overkill. You can simply use Parquet files with DuckDB (it doesn't have Iceberg write support yet either) to create Parquet files on your data lake:
-- DuckDB
COPY (SELECT * FROM './my_data.csv') TO 's3://my_data_lake/output.parquet' (FORMAT PARQUET);
and map them as external tables in Snowflake as follows:
-- Snowflake
CREATE EXTERNAL TABLE new_table
WITH LOCATION = @mystage/my_data_lake/
FILE_FORMAT = (TYPE = PARQUET)
Transformation with Iceberg
For SQL-based transformations, Snowflake supports materialized views for quite a while but my experience with them is not great.
However; they recently released support for dynamic tables, which lets you create pre-aggregated tables declaratively in SQL.
The TARGET_LAG property is pretty interesting. It keeps track of underlying tables and refreshes the table based on the lag you set.
You can optionally refresh the dynamic table on-demand and unlike materialized views, it's much more efficient as it keeps track of the underlying tables and does the refreshing in the background.
Here is how you can use it in combination with Iceberg tables:
CREATE DYNAMIC ICEBERG TABLE my_transformed_table
TARGET_LAG = '15 minutes' -- optional, you can refresh it manually as well
WAREHOUSE = 'compute_xs'
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'your_data_lake_volume'
BASE_LOCATION = 'my_transformed_table'
REFRESH_MODE = auto
INITIALIZE = on_create
AS
SELECT date_trunc('hour', sales_date) as hour, product_name, sum(revenue) as total_revenue FROM staging_table GROUP BY 1, 2;
If you need complex transformations in SQL that are DAG-based, dbt is the most common transformation tool used within Snowflake. I'm hoping the next release of dbt will support Iceberg tables as well, you can keep track of the status here.
If you're looking for more than just SQL, Snowpark is your friend. It enables you to use Python, and Java or bring your containers into Snowflake environment. For Python-based transformations, Snowflake's API is pretty similar to Pandas while Java / Scala API is similar to Spark.
That being said Snowpark is still relatively new so if you're already using Spark and want to leverage its extensive ecosystem, you can write your DataFrames back to Iceberg tables and use Snowflake's object storage catalog to create Iceberg tables in Snowflake, as I mentioned above.
Querying with Iceberg
This is where I think DuckDB shines. If you create the Dynamic Iceberg tables and know that your tables don't have more than 100M rows, you can use DuckDB to query the tables locally. Here is an example DuckDB query on your Snowflake table, that doesn't require an active warehouse:
INSTALL iceberg;
LOAD iceberg;
CREATE SECRET ( TYPE GCS, KEY_ID '{HMAC_KEY}', SECRET '{HMAC_SECRET}' );
SELECT date_trunc('month', product_category),
sum(total_revenue)
FROM iceberg_scan('gs://my-iceberg-data-lake/my_transformed_table')
That being said, for ad-hoc queries on huge datasets that have billions of rows, Iceberg tables are no different than Snowflake tables when it comes to querying and their performance is on par with Snowflake's native data format.
SELECT date_trunc('month', product_category),
sum(total_revenue)
FROM my_transformed_table
If your team is building a data application, and serving the data via a BI tool, you have a variety of options to use any other tool that supports Iceberg.
One important note is that Snowflake catalog doesn't expose metadata.json file for Iceberg tables, the output has the following directory structure:
> data
> data_file.parquet -- data files
> metadata
> {timestamp}.metadata.json -- includes schema
{timestamp}.metadata.avro -- includes statistics
> version-hint.text -- last version
If you need the direct URI for the metadata file to the Iceberg table, here is how you can generate it:
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('my_transformed_table');
The file is generated lazily if it doesn't exist yet:
+-----------------------------------------------------------------------------------------------------------+
| SYSTEM$GET_ICEBERG_TABLE_INFORMATION('DB1.SCHEMA1.IT1') |
|-----------------------------------------------------------------------------------------------------------|
| {"metadataLocation":"s3://mybucket/metadata/v1.metadata.json","status":"success"} |
+-----------------------------------------------------------------------------------------------------------+
This operation doesn't require a running warehouse and it's useful when you use Clickhouse or BigQuery BigLake.
Which Compute Should I Use?
There is no one-size-fits-all answer to this question. Almost all the advanced data-warehouses support Iceberg tables natively nowadays and comparing Databricks and Snowflake, there is no clear winner in terms of performance. It all boils down to ecosystem and developer experience thanks to Iceberg's interoperability.
Snowflake is intuitive and easy to use thanks to the SQL-first approach, while Databricks is more flexible and has a bigger ecosystem thanks to Spark. If you're a data person who likes to use Cloud SQL and don't want to worry about the infrastructure, Snowflake is the way to go. If you're a data engineer who likes to use Python and wants to have more control over the infrastructure, Databricks is the way to go.
If you're building a customer-facing data application from your data lake, both Snowflake and Databricks will be expensive due to their pricing tied to the serverless compute model. I would suggest using Clickhouse or DuckDB hosted in your cloud (AWS, GCP, Azure, etc.) if you need a high throughput and cost-efficient alternative.
An interesting player for me is DuckDB because as a data engineer using a fancy laptop with 32GB+ RAM, I would rather use my machine and get the best of two worlds without paying for any computing costs. Data lake's Egress cost should be minimal in this case as we're not pulling billions of records and Iceberg supports predicate/projection pushdown and partitioning already. If I know my machine is not enough, I rather use a combination of Cloud Data Warehouses depending on my team's expertise.
If you prefer picking the technology based on its popularity, (thus ecosystem) here are the trends:
