Part 1: Comparing the pricing models of modern data warehouses
I had a chance to learn more about the up-to-date comparison of data warehouses while working on Universql. It's hard to do benchmarks for databases, but it's harder to do comparisons on their pricing. There are 3 major things you need to consider:
Considerations
Storage cost
Often providers such as Redshift and Snowflake use their own proprietary database formats so while the pricing is based on the data volume, it's hard to estimate how much data space you will need before actually using them. However; looking at the storage pricing for Snowflake, S3, and BigQuery the margin is pretty small for the storage. From Snowflake, we know that the storage cost is usually < 10% of the total cost of data warehouses. Also, the compaction for the files doesn't make a huge difference (~30%) in the storage according to Clickbench.
If you use Iceberg Tables, you can use the same table in all the data warehouses.
Compute cost
Some charge based on the data your query processed, and some charge based on the compute units you use under the hood (warehouse, slot, etc.) The performance for specific operations such as ingestion, transformation, querying small tables vs big tables, and the use of SQL syntax such as WINDOW functions have a huge impact on the cost due to the way underlying engines implement them. Also, the performance/cost changes over time with the software updates.
Decoupling storage from compute is important because unless you have an anti-pattern use-case, the most expensive pillar (> 90%) is the compute cost in all the data warehouses. While For compute, here is the terminology they use for compute:
| Compute Capacity / Minimum cost of unit | Data Processing / Price per TB | |
|---|---|---|
| Snowflake | Warehouse ($2 / hour) | - |
| AWS Athena | DPU ($3.6 / hour) | Data scanned ($5) |
| AWS Redshift Serverless | RPUs( $3.65 / hour) | - |
| Google BigQuery | Slots ($2 / hour) | Data scanned ($6.25) |
| Databricks | DBU ($2.8 / hour) | - |
Data Transfer
Considering you use a cloud provider already and store your data in there, they incur egress/ingress if you're transferring the data in between different regions. If you don't use compression or use row-oriented formats such as CSV, JSON instead of columnar formats such as Parquet, ORC both storage and data transfer cost will be significantly higher. However; the native data formats in data warehouses use columnar formats which are more efficient in terms of storage and data transfer.
Performance Impact on Query Engine
Also keep in mind that the recent findings show that the compute performance highly varies based on the workloads. It's easier to get the data into Snowflake but the transformation is expensive.
Snowflake and Redshift have both published representative samples of real-world queries, and the way people actually use these systems is INTERESTING. The main workload is ingest and transformation! pic.twitter.com/GgnYOfxVtO
— George Fraser (@frasergeorgew) September 17, 2024
Snowflake
Warehouse
Snowflake uses Warehouses for hardware abstraction. They are mapped to EC2 instances on AWS, VM machines on GCP and Azure. They scale both horizontally and vertically as you run queries on these warehouses and auto-start & auto-suspend based on your configuration. While one warehouse can run multiple queries simultaneously, queries try to use the resources as much as possible.
The cost is fairly predictable because warehouse concept let's you tune in between latency and performance. If you want to run queries 2x efficiently, just switch to bigger warehouse (ex: from x-small to small)
On the flip side, you pay for the warehouse during auto-suspend and your queries suffer 1-2 seconds of latency for the auto-start. Even if you run a query takes takes 5 seconds to run, you pay for a warehouse 60 seconds at minimum so you often need to optimize your warehouse as you scale. This work is non-trivial if you're not familiar with Snowflake and there are even startups (Select.dev, Keebola etc.) that help you optimize your warehouse usage.
Snowflake charges based on credits, which costs $2 today. (2024-09) You can scale in or out (multi-clusters), by giving you the flexibility to tune your workload. Here are Snowflake warehouse types:
Snowflake has Streams and Tasks, which let you create workflows based on event and time-based triggers. For incremental processing, you have these options:
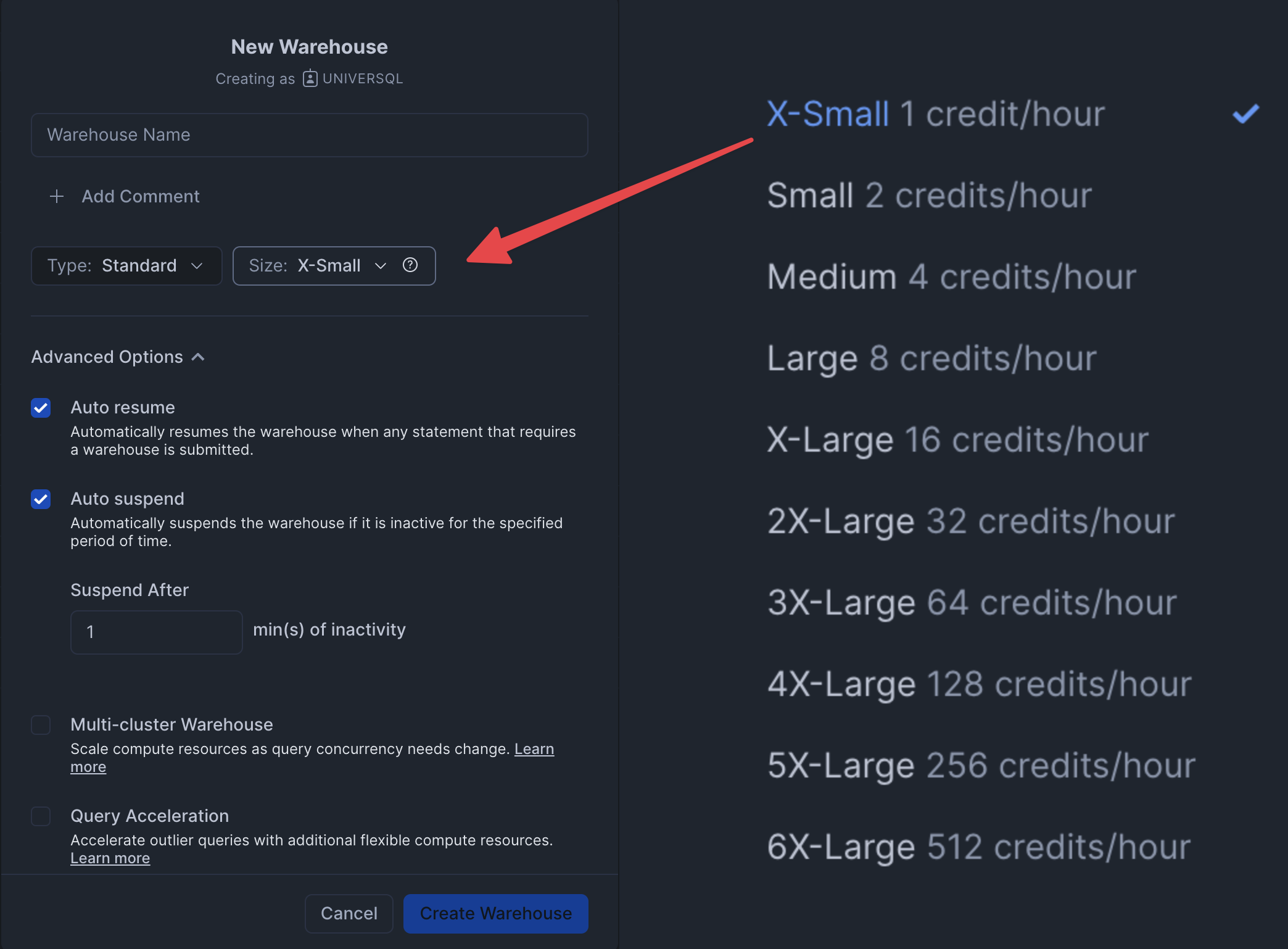
Snowflake doesn't offer any discount for the reserved capacity but offers a discount for the credits you buy in advance depending on your negotiation. You can use your AWS, Azure, and GCP credits to pay for Snowflake.
Snowflake Serverless tasks
Snowflake has Serverless Tasks feature, which automatically provisions warehouses under the hood for you to scale as your query gets more expensive. It costs 0.9x of the warehouse cost for the same duration. Keep in mind that a single warehouse can run multiple queries concurrently on Snowflake so it's indeed more expensive than using warehouses.
In order to use Serverless Tasks, you need to create a task, using CREATE TASK syntax. Tasks are suitable if you would like to run the same query based on an internal as a workflow but Snowflake doesn't support serverless model for typical SELECT queries. I believe soon enough they will release such feature to keep up with the competition.
AWS Redshift Serverless
Redshift Serverless is AWS's new product, superseding Redshift we know of. It decouples storage from compute and has native integration with S3. I didn't include AWS Athena to the comparison because Redshift Serverless seems to outperform Athena.
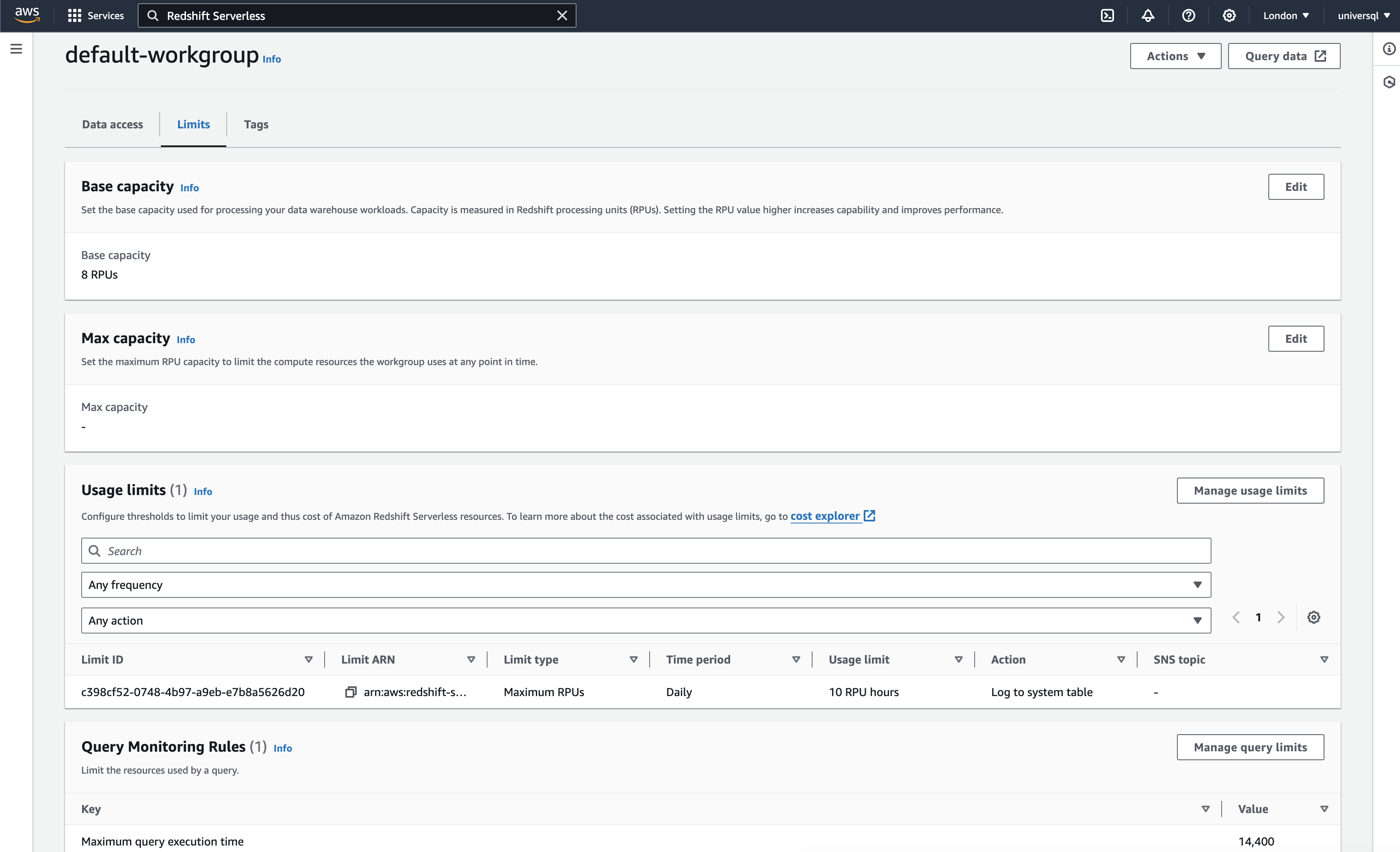
You need create a workspace, defining base capacity RPUs based on your allocations. The minimum for base is 8, which costs and the RPU price is $0.467, which makes $3.65 per hour.
While it's serverless, Redshift charges you a minimum of 60 seconds when you start using the compute. It's similar to Snowflake in that sense. It scales to zero when you don't query the tables.
AWS Athena
AWS Athena is a Headless Data Warehouse, using Glue as Data Catalog and S3 as the data lake. It charges you based on the data scanned for the query by default but you can use provisioned capacity to manage the workloads in a serverless way. The minimum cost is $3.6 per DPU per hour.
Databricks
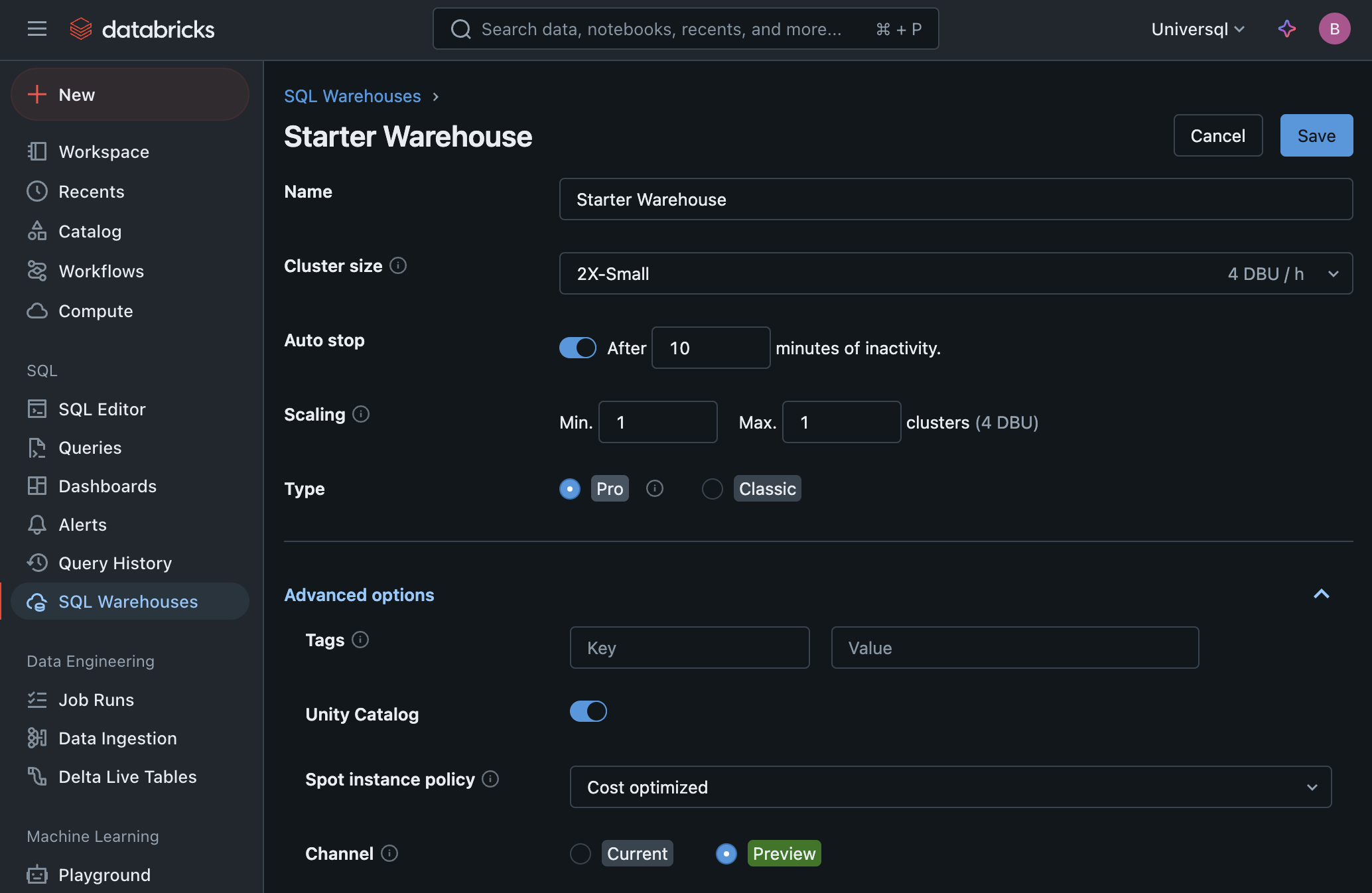
Databricks uses the BYOC (Bring-your-cloud) model. You install Databricks in your cloud provider, and it provisions a Kubernetes cluster for you. It runs a minimum of 4 nodes in the cluster even if you don't use it so it doesn't scale to zero unlike all the other options. The pricing is based on DBU, Databricks Unit. The minimum cost is $0.7 per DBU, which makes $2.8 per hour.
Google BigQuery
BigQuery has two pricing models, by default it's demand based pricing, which is simply TBs scanned for the query. While you can get a great performance, it comes at a cost. Your innocent query select * from fact_table limit 1 can end up processing TBs of data if you're not careful but luckily BigQuery console provides you with some stats before running the query.
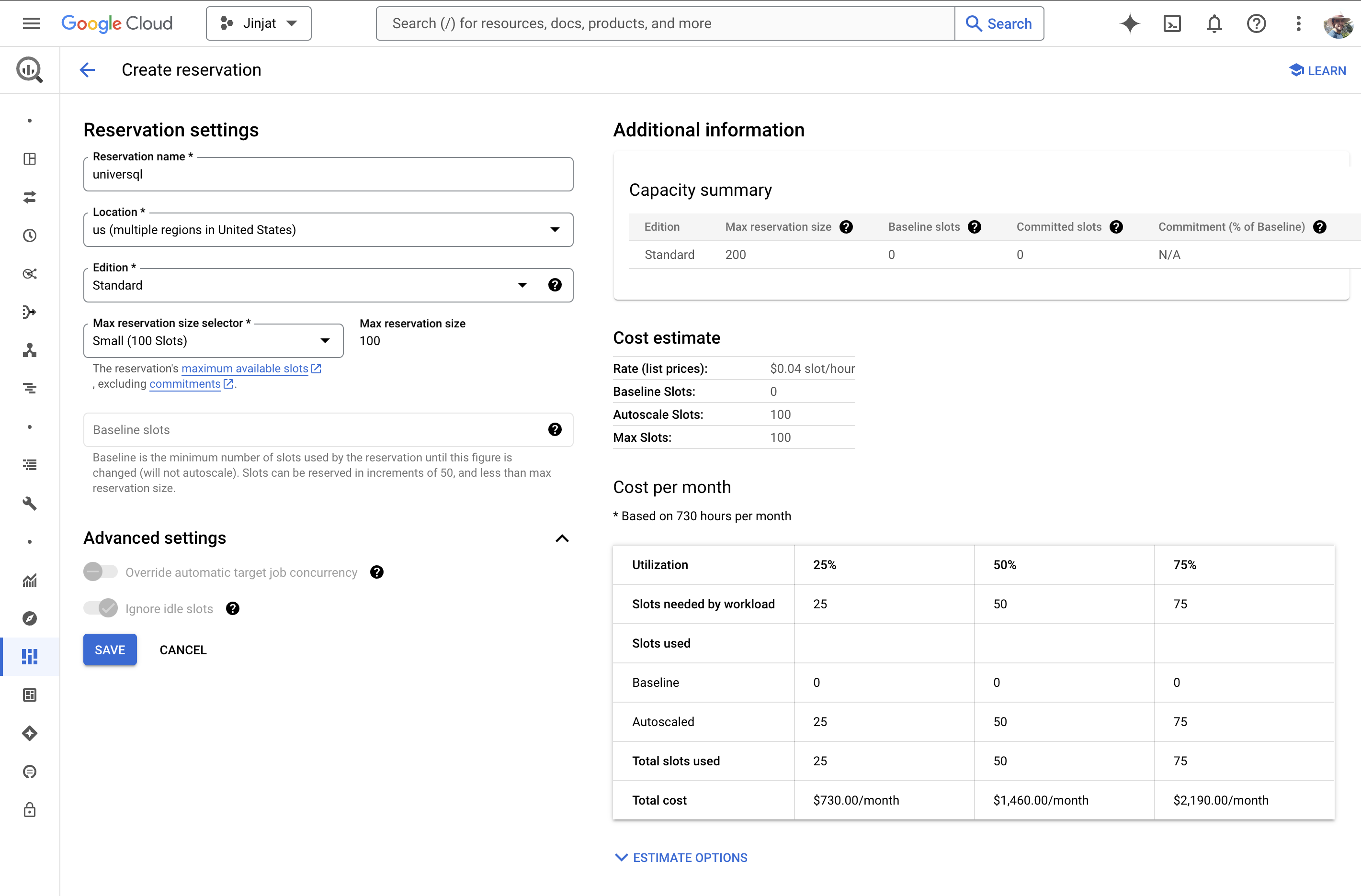
With Capacity-based pricing, you can allocate slots for your BigQuery project and they threshold the CPU time used at a given interval. I would like to think of slots at the CPU units. It's cost-efficient compared to Snowflake, due to BigQuery's autoscaler.
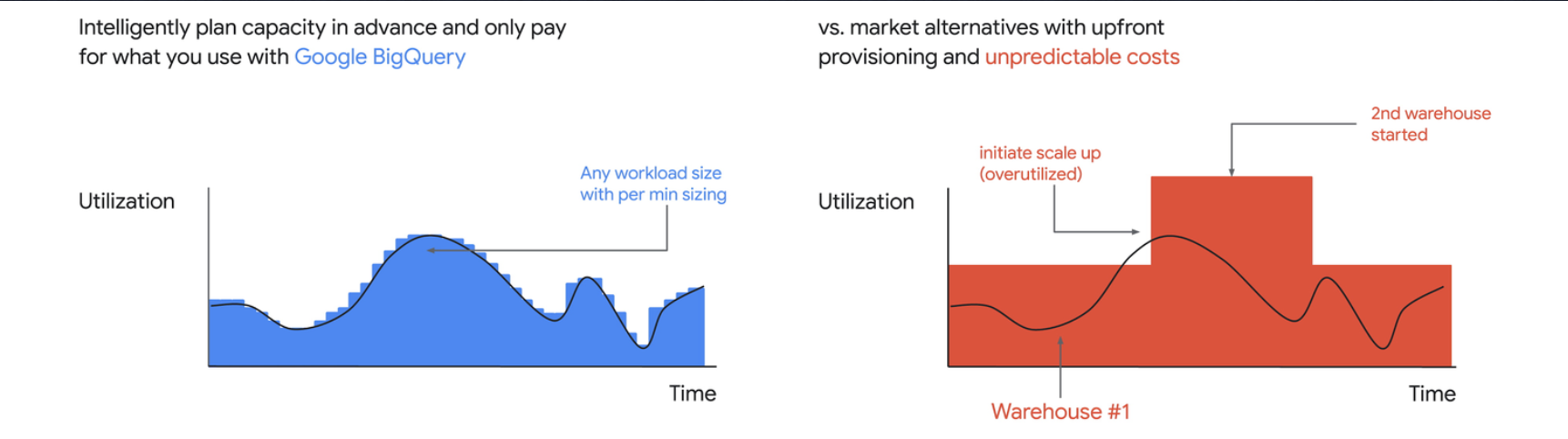
The minimum reservation is 50 slots, with the current price (2024-09, $0.04), and the minimum cost unit is $2 / hour if you run it for a full hour. You don't need to worry about things like cold start performance issues or optimizing warehouse usage. Each query consumes the capacity defined for the project you have the reservation. It perfectly scales to zero when the tables are not queried.
Related Work
So What?
The pricing and storage are not much different between the data warehouses. The compute cost is the most expensive part of the data warehouses. The performance of the queries highly varies based on the workloads and where the data is so it's usually best to do discovery with all these solutions and pick the tech that your team thinks is the best.
Next up, we are: